

What is Multimodal AI? Multimodal AI refers to artificial intelligence that can process and integrate different types of data like text, images, audio, and video simultaneously. This enables the AI to understand complex information in a more comprehensive way, much like a human would. In this article, we’ll explore what is multimodal AI, how it works, its components, and its applications across various industries.
Core Principles to Understand What is Multimodal AI
- Multimodal AI integrates various data types, such as text, images, and audio, to enhance decision-making and provide a comprehensive understanding of information.
- Key components of multimodal AI systems include input modules, fusion modules, and output modules, which work together to process and analyze diverse data effectively.
- Real-world applications of multimodal AI span multiple industries, including healthcare, autonomous vehicles, and retail, where it improves diagnostic accuracy, driving safety, and customer experiences.
Understanding Multimodal AI

Multimodal AI involves the ability of AI systems to handle various types of data at the same time. This capability allows for the integration of different information sources. Unlike traditional unimodal AI, which relies on a single type of data input, multimodal AI combines text, images, audio, and video to create a more holistic and nuanced understanding of information. Emulating human-like processing, multimodal AI refers to a deeper level of contextual understanding, enhancing decision-making and yielding richer, more comprehensive outputs. This approach is often referred to as a multimodal model.
One of the key strengths of multimodal AI is its ability to integrate various types of data, such as natural language processing for text, computer vision for images, and speech recognition for audio. This integration enables artificial intelligence to interpret and analyze a more diverse and richer set of information, improving the accuracy and relevance of its responses. For instance, a multimodal AI system can generate a written summary from an image or create an image based on a textual description, showcasing its versatile capabilities.
Analyzing multiple data types simultaneously, multimodal AI enhances the interpretation of complex scenarios, leading to better decision-making outcomes. This is particularly valuable in fields like healthcare, autonomous vehicles, and retail, where understanding and integrating diverse data sources can significantly improve performance and results.
Multimodal AI vs. Unimodal AI
While multimodal AI processes multiple data types simultaneously, unimodal neural networks are limited to a single type of data input. Traditional unimodal AI systems, tailored for specific functions, often fall short in complex scenarios that require a broader understanding and integration of information. For example, a unimodal AI system designed solely for text analysis may struggle to provide accurate insights when visual or audio data is also relevant.
In contrast, multimodal AI systems excel in such scenarios by integrating different modalities to create a more comprehensive understanding. These multimodal capabilities allow multimodal AI work to perform versatile tasks, such as analyzing text, images, and audio simultaneously, leading to richer responses and enhanced decision-making accuracy.
The integration of multiple types of data streams not only improves performance to perform tasks but also opens new possibilities for innovative applications in various industries.
How Multimodal AI Systems Work
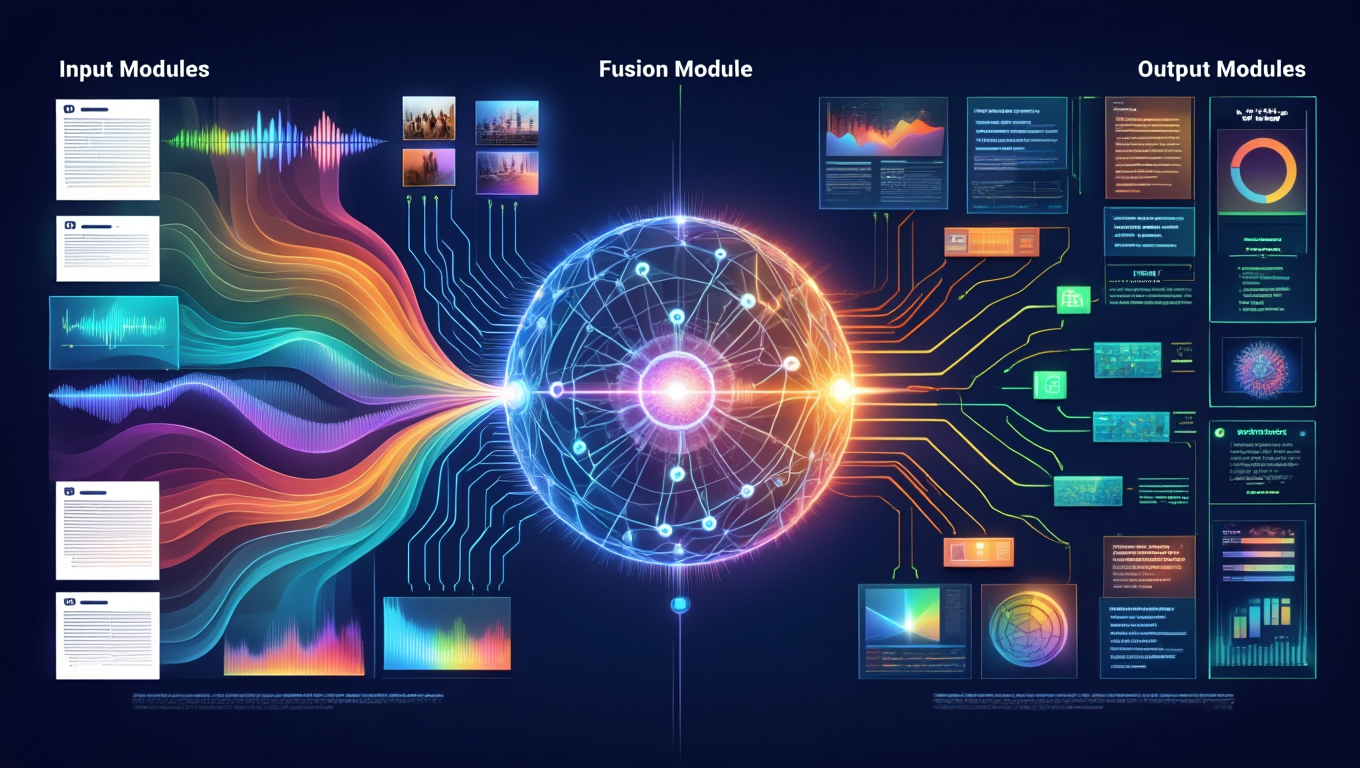
Multimodal AI systems are built on three main components: input modules, fusion modules, and output modules. Each of these components plays a critical role in processing and integrating diverse data types to generate meaningful outputs. The input module gathers raw data from various sources, the fusion module combines and processes this data, and the output module produces the final results.
These advanced systems utilize separate neural networks for each data type, ensuring that the unique characteristics of text, images, audio, and other modalities are effectively captured and processed. By seamlessly integrating these components, multimodal AI systems can analyze and interpret complex data from multiple sources, providing richer and more accurate insights.
Input Modules
The input modules in multimodal AI are essential components that handle different types of data inputs, such as text, images, audio, and video and audio data. These modules convert various types of raw data into usable formats through specific feature extraction techniques, ensuring that the output is suited for subsequent processing. For example, textual data might undergo natural language processing, while images are processed through computer vision techniques, taking into account the sensory inputs involved.
Feature extraction techniques vary depending on the type of data, highlighting the importance of tailored approaches for each modality. Effectively converting raw data into useful multiple formats, input modules lay the foundation for the fusion module to combine and process the data efficiently.
Fusion Module
The fusion module in multimodal AI is designed to combine, align, and process data from different modalities into a single, cohesive representation. This integration of features from various modalities is crucial for creating a unified understanding of the input data. For instance, in autonomous vehicles, the fusion module interprets complex driving environments by integrating sensor data and map information, enhancing the vehicle’s ability to make informed decisions.
Real-time data fusion from multiple sensors is essential for applications like autonomous driving, where immediate and accurate understanding of the surroundings is critical for safety and performance. The fusion module’s ability to merge features from different modalities ensures that the AI system can provide a comprehensive analysis of the data.
Output Module
The output module in multimodal AI processes the unified representation created by the fusion module to generate actionable results. This module:
- Transforms the combined data into meaningful outputs
- Generates images
- Produces text summaries
- Performs specific tasks based on the integrated data
In healthcare, for example, multimodal AI applications can analyze electronic health records alongside medical images to produce more accurate treatment plans, demonstrating the practical benefits of effective output generation.
The output module’s ability to deliver precise and actionable outcomes is a key factor in the success of multimodal AI systems.
Key Technologies in Multimodal AI
Several key technologies drive the functionality and evolution of multimodal AI systems. ImageBind, for instance, can integrate data from multiple types of input to produce output in various modalities, showcasing the versatility of modern multimodal AI.
As of 2025, multimodal AI has advanced significantly, with models like OpenAI’s GPT-5 offering real-time understanding and generation across text, images, audio, and video. GPT-5 builds on earlier models such as GPT-4 Vision and Google’s Gemini, introducing features like dynamic reasoning modes, longer context handling, and improved safety and accuracy. These capabilities highlight how unified, multimodal frameworks are becoming more responsive, coherent, and context-aware.
Technologies like CLIP also demonstrate the effectiveness of linking textual descriptions with corresponding images for tasks such as captioning, recognition, and classification, underscoring the wide range of approaches driving progress in multimodal AI.
Real-World Applications of Multimodal AI

The real-world applications of multimodal AI are vast and varied, impacting numerous industries. In healthcare, multimodal AI enhances diagnostic accuracy by integrating data from diverse sources such as medical imaging, patient records, and lab results.
In autonomous vehicles, multimodal AI systems analyze data from cameras, LiDAR, GPS, and sensors to enable real-time decision-making and safe navigation. In retail, multimodal AI provides personalized experiences, operational efficiency, and improved customer satisfaction by analyzing various data types, including customer behavior and purchase history.
These applications demonstrate the transformative potential of multimodal AI in enhancing decision-making and improving outcomes across different sectors.
Healthcare
In healthcare, multimodal AI plays a crucial role in enhancing medical diagnostics by integrating diverse datasets such as:
- Medical imaging (e.g., X-ray images that provide critical visual insights)
- Patient records (including patient history and physician notes that offer contextual information)
- Lab results
This integration leads to improved diagnostic accuracy and early disease detection, ultimately contributing to better patient outcomes.
Combining these various data sources, multimodal AI creates a more comprehensive understanding of patient conditions through multiple modalities, leading to more effective treatment plans and efficient healthcare systems.
Autonomous Vehicles
Autonomous vehicles rely on multimodal AI to integrate and analyze data from multiple sources, including:
- Cameras
- LiDAR
- GPS
- Sensors
This real-time processing and data integration are essential for safe and effective autonomous driving, as the AI system needs to understand and react to complex driving environments instantly.
The ability of multimodal AI to merge data from various sensors ensures that autonomous vehicles can navigate safely, make informed decisions, and adapt to changing conditions on the road. This integration is critical for the advancement of autonomous driving technology and its widespread adoption.
Retail
In the retail sector, multimodal AI enhances:
- Personalized experiences by analyzing diverse data sources such as social media interactions, purchase history, and in-store activities
- Operational efficiency through optimized inventory management
- Customer satisfaction by delivering tailored recommendations and improving overall shopping experiences
Popular Multimodal Models
Several popular multimodal AI models exemplify the capabilities and potential of this technology. GPT-4 Vision and Gemini are unified models that can understand and generate content across various modalities, including text, images, audio, and video. These models leverage advanced machine learning techniques to process and integrate diverse data types, providing accurate and coherent outputs. Gen ai technology enhances these capabilities further.
The LLaVA ai model, for instance, merges vision and language understanding, enhancing the querying capabilities in chat applications. These multimodal generative AI systems are capable of producing responses, images, videos, and audio, demonstrating their versatility and effectiveness in various applications.
Benefits of Multimodal AI

Multimodal AI offers numerous benefits, particularly in complex scenarios that require understanding multiple data inputs simultaneously. Combining various data types, multimodal AI enhances user interactions and improves the accuracy and relevance of its responses. For example, AI assistants that can process video and audio simultaneously provide more intuitive and natural interactions.
In industries like healthcare, multimodal AI frameworks can significantly improve patient outcomes by integrating data from electronic health records, medical imaging, and other sources. In finance, multimodal AI enhances efficiency by automating risk assessments and fraud detection. Additionally, multimodal AI can drive targeted marketing strategies by analyzing customer behavior from various data sources, leading to more effective campaigns.
Applications of multimodal AI include:
- Improving patient outcomes in healthcare by integrating data from electronic health records, medical imaging, and other sources
- Enhancing efficiency in finance through automating risk assessments and fraud detection
- Driving targeted marketing strategies by analyzing customer behavior from various data sources, resulting in more effective campaigns
These systems facilitate more natural and intuitive interactions with users by understanding gestures and voice commands, rather than relying solely on text input. This user-friendly design enhances the overall experience and broadens the applicability of AI technologies across different sectors, particularly in the field of human computer interaction.
Challenges in Multimodal AI
Despite its many benefits, multimodal AI faces significant challenges:
- Creating large-scale, well-aligned multimodal datasets is a labor-intensive and costly process.
- Data collection and labeling are expensive and time-consuming, posing a major hurdle for widespread implementation.
- The computational demands for training multimodal models are substantially higher compared to unimodal counterparts, requiring extensive GPU/TPU hours.
Poor data alignment and managing noise levels across different modalities can significantly impact model performance, potentially reducing accuracy on tasks involving out-of-distribution multimodal data and missing data. The architectural complexity of integrating diverse data structures necessitates innovative model designs and careful tuning. These challenges highlight the need for ongoing research and development to optimize multimodal AI systems.
Future Trends in Multimodal AI
The future of multimodal AI is poised for exciting advancements. Real-time processing is crucial for applications like autonomous driving, where immediate data integration is necessary for safe operation. Multimodal AI systems are expected to offer a deeper understanding of complex real-world situations by processing various types of data simultaneously.
The rapid evolution of multimodal AI technologies will enable these systems to solve complex problems in a human-like manner, enhancing their applicability across different fields. With a projected growth rate of over 30% CAGR from 2024 to 2032, multimodal AI is set to become increasingly important in various industries, driving innovation and improving outcomes.
Summary
Multimodal AI represents a significant leap forward in the field of artificial intelligence, offering the ability to process and integrate multiple types of data simultaneously. This comprehensive guide has explored how multimodal AI works, its key technologies, real-world applications, and the challenges it faces. By combining various data types, multimodal AI enhances decision-making, improves accuracy, and provides richer, more nuanced insights.
As we look to the future, the potential of multimodal AI to revolutionize industries and improve our interactions with technology is immense. Embracing these advancements will pave the way for more intuitive, efficient, and impactful AI applications, shaping the future of technology and society.